by AD Tejpal
This sample db demonstrates use of check box array for populating a junction table serving many to many relationship between clients and training courses. Data is stored in normalized manner in tables T_Clients, T_Courses and T_ClientCourses. No temporary table is needed.
Two styles of user interface are demonstrated:
1 - Normal Style (Using Virtual Records Matrix):
-------------------------------------------------
1.1 - Client particulars are displayed in the parent form while all available course options are displayed in a subform, as a matrix of virtual new records.
1.2 - As and when the user clicks a check box into selected state against desired course in the subform, the row in question gets converted into a freshly entered actual record in the junction table.
1.3 - Similarly, if a check box is clicked into a de-selected state, corresponding record in junction table gets deleted. This is accompanied by a virtual new record getting displayed in lieu of the recently deleted actual record (At all times, the subform matrix continues to display all available course options).
1.4 - Total number of courses opted for current client as well as the grand total for all clients are also displayed in the parent form
2 - Spreadsheet Style - Datasheet View (Using Crosstab Query):
-----------------------------------------------------------------
2.1 - Adequate number of check boxes along with child labels are inserted in the form at design stage. This is a one time exercise, using the subroutine P_AddControls().
2.2 - Each check box column of this datasheet form (used as a subform) represents an individual course. A crosstab query, based upon Cartesian join between tables T_Clients and T_Courses, serves as the record source.
2.3 - As and when the user clicks a check box into selected state in desired course column, a record with appropriate values for ClientID and CourseID gets added to the junction table.
2.4 - Similarly, if a check box is clicked into a de-selected state, corresponding record in junction table gets deleted.
2.5 - First three columns display client name, list of courses opted and total number of courses opted respectively. These three columns are frozen so as to always remain in view while the user moves across check box columns representing individual courses.
2.6 - Third column depicts total number of courses opted for each client. Bottom cell of this column shows the overall total courses opted for all clients. Overall total is also depicted within parenthesis in header caption for this column, so as to always remain in view despite vertical scrolling.
2.7 - For each course, total number of clients who have opted for it, is depicted within parenthesis in the caption for respective column header, so as to always remain in view despite vertical scrolling.
You can find this sample here:
http://www.rogersaccesslibrary.com/forum/Form-mtomviacheckboxarray_topic553.html
.
Wednesday, December 29, 2010
Monday, December 27, 2010
Domain Function Examples: Numbered Query With DCount
So far in this series on Domain Functions, I've discussed the general syntax (Domain Functions Demystified) and problems involved in building criteria expressions (Domain Functions Demystified: Criteria Expressions). Unfortunately, many of the examples I've given are relatively trivial. So for my next few blog posts, I thought I'd give what I consider truly useful applications of domain functions.
Other Examples:
- Simulate AutoNumber with DMax
- Running Sum with DSum
- Difference Between with DMax
- Rolling Average with DAvg and DCount
- Begin Date and End Date from Effective Date
One interesting problem is how to create a numbered sequence in a query, that is, have each record numbered sequentially.
This is fairly easy to accomplish in an Access report. All you need to do in a report is add an unbound text box. In the control source, put =1 and set the Running Sum property to Over All.

But suppose you don't want to do it in a report. Suppose you want to do it directly in a query. There are two different ways to accomplish this. The first uses the Domain Aggregated function DCount and the second uses a Correlated Subquery. Since this series is devoted to domain functions, I'm going to concentrate on that.
Both of these methods require a unique column in the table to create the sequence on. This could be the Primary Key field or any field that has a Unique Index. In the Customers table, there are two such columns, CustID (Customer ID), which is the primary key, and CustName (Customer Name), which has a unique index.
DCount Method
Domain Aggregate functions are an Access-only method to return statistical information about a specific set of records, whether from a table or query. DCount in particular will return the number of records in a given recordset. It has three arguments: 1) an expression that identifies a field, 2) a string expression that identifies a domain (that is, the table or query), and 3) a Criteria, which is essentially an SQL Where clause without the word WHERE.
The specific DCount expression we're going to use looks like this:
DCount("CustID","Customers","CustID <=" & [CustID]
In the query, it will look like the following.
SELECT DCount("CustID","Customers","CustID <=" & [CustID]) AS Sequence,
CustName, CustPhone, CustID
FROM Customers
ORDER BY CustID;
CustName, CustPhone, CustID
FROM Customers
ORDER BY CustID;
The Order By clause in the query is important. This will sort the query on the CustID field. We'll need to have that order to use the criteria argument in the DCount.
Here's how it works.
So in the first record, the CustID is 1. So the DCount opens the domain (essentially opens the Customers table again) and it sees that there is only 1 record whose CustID is less than or equal to 1. So it returns 1.
Then it processes the second record. The CustID of that record is 3, and the DCount function sees that there are only 2 records which have an CustID whose value is less than or equal to 3. So it returns 2.
It is not necessary that the Order By field is an unbroken sequence. As long as that field has unique values and is sorted, it will work.
The output of this query looks like Figure 1. Strictly speaking, you wouldn't need to show the CustID number in the query at all. However, I included it to show that while the order is the same as CustID, the sequence number does not have gaps in the numbering sequence.

You don't need to use a number field as your Order By field. You can sort on text fields and number the query as well.
If you wanted to sort on the Customer Name field (CustName), you would change the DCount to the following:
DCount("CustName","Customers","CustName <='" & [CustName] & "'")
The output would look like this:

Subquery Method
As I said, this can also be done with a correlated subquery, which I may discuss at a later date. However, you can find both methods on my website in this sample: NumberedQuery.mdb.
.
Wednesday, December 22, 2010
Domain Function Example: Simulate AutoNumber with DMax
So far in this series on Domain Functions, I've discussed the general syntax (Domain Functions Demystified) and problems involved in building criteria expressions (Domain Functions Demystified: Criteria Expressions). Unfortunately, many of the examples I've given are relatively trivial. So for my next few blog posts, I thought I'd give what I consider truly useful applications of domain functions.
Other Examples:
While there are several ways to do this, one of the simplest is to use a DMax function in as the Default Value of a control on a form.
So let's say I want to generate my own sequential Product Number for a product table. I can create a form based on the Product table, and create a textbox bound to the ProductNum field. In the DefaultValue property, I would put the following domain function.
=DMax("ProductNum","Product")+1

This opens the Product table, find the largest ProductNum and add 1 to it. That's it.
It becomes a little more complex in a multi-user environment, since two or more people may try to select the same number at the same time. There's a fairly simple solution for multi-user collisions, but it requires a tiny bit of VBA code.
First of all, the field you're incrementing must be a Primary Key or have a Unique Index on it. When you try to save the record, if the number has already been used, it will throw an error (3022). You can trap this error in the OnError event of the form:
Private Sub Form_Error(DataErr As Integer, Response As Integer)
This calls the IncrementField user-defined function, which looks like this:
Function IncrementField(DataErr)
So, if you have a collision, the IncrementField function will go out and grab another.
You can find a working example of both the single-user method and the multi-user method on my website here: AutonumberProblem.mdb.
.
Other Examples:
- Numbered Query with DCount
- Running Sum with DSum
- Difference Between with DMax
- Rolling Average with DAvg and DCount
- Begin Date and End Date from Effective Date
Single-User Application
While there are several ways to do this, one of the simplest is to use a DMax function in as the Default Value of a control on a form.
So let's say I want to generate my own sequential Product Number for a product table. I can create a form based on the Product table, and create a textbox bound to the ProductNum field. In the DefaultValue property, I would put the following domain function.
=DMax("ProductNum","Product")+1

This opens the Product table, find the largest ProductNum and add 1 to it. That's it.
Multi-user Application
It becomes a little more complex in a multi-user environment, since two or more people may try to select the same number at the same time. There's a fairly simple solution for multi-user collisions, but it requires a tiny bit of VBA code.
First of all, the field you're incrementing must be a Primary Key or have a Unique Index on it. When you try to save the record, if the number has already been used, it will throw an error (3022). You can trap this error in the OnError event of the form:
Private Sub Form_Error(DataErr As Integer, Response As Integer)
Response = IncrementField(DataErr)
End Sub
This calls the IncrementField user-defined function, which looks like this:
Function IncrementField(DataErr)
If DataErr = 3022 Then
Me!ProductID = DMax("ProductID", "Product") + 1
IncrementField = acDataErrContinue
End If
End Function
So, if you have a collision, the IncrementField function will go out and grab another.
You can find a working example of both the single-user method and the multi-user method on my website here: AutonumberProblem.mdb.
.
Monday, December 13, 2010
Domain Functions Demystified: Criteria Expressions
In my last post: Domain Functions Demystified: Introduction, I discussed the structure and syntax of the domain functions in Microsoft Access. The basic syntax is as follows:
DFunctionName("<Fieldname >", "<RecordSource>", "<Criteria Expression>")
- Fieldname refers to the field against which the function will be applied.
- RecordSource refers to a table or query from which the records will be pulled.
- Criteria Expression is basically an SQL Where clause without the WHERE keyword. (optional)
Criteria Expressions
The third argument, the Criteria expression, is the most confusing, so it might be useful to take a closer look at them.A Criteria Expression is an SQL Where clause without the "WHERE" keyword. Just as in a Where clause, sometimes the value of the expression needs to be delimited, sometimes it doesn't. What determines the delimiter (or lack of one) is the data type of the field.
Numeric
Numeric fields don't need a delimiter. So we can use:"[OrderNum] = 1"
for the criteria expression. (Although remember that the entire expression must be enclosed in quotes.) Substituting a variable (in this case the name of a bound textbox on a form) for the value yields this:
"[OrderNum] = " & Me.txtOrderID)
Dates
Date fields require the date delimiter. In Access, that's the pound sign or hash mark (#). So with a hard-coded value, my criteria might look something like this:"[OrderDate] = #1/1/2010#"
With a variable, it would look like this:
"[OrderDate] = #" & Me.txtOrderDate) & "#"
Strings
String or text values are the trickiest type and cause the most confusion. String values must have string delimiters: either quote marks (") or apostrophe ('), but since the entire argument must also be encased in string delimiters you have to somehow tell the expression evaluator which string is which. So suppose I want to use CustName in my domain function.[CustName] = "Roger Carlson"
So if I put quotes around the whole thing, I get
"[CustName] = "Roger Carlson""
This will cause an error, however, because of the way the interpreter reads the quotes. In order to put a quote within a quoted string, you have to double the quotes:
"[CustName] = ""Roger Carlson"""
So now, I need to replace the explicit Roger Carlson with the variable:
"[CustName] = "" & Me.txtCustNum & """
But this will also cause an error because I now have two different strings that have to be concatenated and the interpreter isn't reading the quotes right again. To fix it, I have to double the inner quotes again:
"[CustName] = """ & Me.txtCustNum & """"
Now, I said you can also do this with apostrophes. So let me repeat the process:
[CustName] = 'Roger Carlson'
can be fixed surrounded with quotes this way and it will not error.
"[CustName] = 'Roger Carlson'"
But adding the variable again:
"[CustName] = ' & Me.txtCustNum & '"
gives us two incomplete strings. We need to add a quote to each:
"[CustName] = '" & Me.txtCustNum & "'"
So either:
"[CustName] = '" & Me.txtCustNum & "'"
or
"[CustName] = """ & Me.txtCustNum & """"
will work.
Now, you might ask, why would you ever use the double quote if the apostrophe will work? Well, if your data can have an apostrophe in it, (like O'Brian) you have to use the double quotes.
ASCII Code
Another possibility is to use the Chr$(34) character (which is the ASCII code for a quote) like this:"[CustName] = " & Chr$(34) & Me.txtCustNum & Chr$(34)
This gives us the opportunity to deal with delimited values of all kinds programmatically. I suppose I could write one of my own, but Ken Getz wrote the classic routine for that. Anything I'd write would simply be a copy, so I'll show his:
(excerpted from "Microsoft Access 2.0 How-To CD" (by Getz, Feddema, Gunderloy,and Haught and published by the Waite Group Press)
Function FixUp (ByVal varValue As Variant) As Variant
'Add the appropriate delimiters, depending on the data type.
'Put quotes around text, "#" around dates, and nothing
'around numeric values.
Dim strQuote As String'Put quotes around text, "#" around dates, and nothing
'around numeric values.
' strQuote contains the ANSI representation of
' a quote character
strQuote = Chr$(34)
Select Case VarType(varValue)
Case V_INTEGER, V_SINGLE, V_DOUBLE, V_LONG, V_CURRENCY
FixUp = CStr(varValue)
Case V_STRING
FixUp = strQuote & varValue & strQuote
Case V_DATE
FixUp = "#" & varValue & "#"
Case Else
FixUp = Null
End Select
End Function
To use this function, copy it into a general module, and then call it like this:
"[CustName] = " & FixUp(Me.txtCustNum)
Using this method, it doesn't matter what data type or delimiter, the function fixes it automatically.
Mixed Apostrophe and Quotes
One last problem. What if you have both embedded apostrophes and quote marks in your string value? For instance, you have a height value which is a string with feet and inches like this: 6' 3". This will cause a problem regardless of which delimiter you use.However, there's a solution for that too. AD Tejpal has developed a comprehensive solution, which you can find here: http://www.rogersaccesslibrary.com/forum/topic113.html
In my next post, I'll look at some in-depth examples of how Domain Functions are used.
.
Wednesday, December 8, 2010
Domain Functions Demystified
Introduction
In Microsoft Access, domain functions work like mini-SQL statements that can be used in queries, forms, reports, or code. Domain functions can also be used in places where SQL statements cannot, like the control source of a textbox. Like an aggregate (or totals) query, the domain functions build a resultset (that is, a set of records) and then apply a function to it. Unlike a query, however, a domain function can return ONLY one value.
In Microsoft Access, domain functions work like mini-SQL statements that can be used in queries, forms, reports, or code. Domain functions can also be used in places where SQL statements cannot, like the control source of a textbox. Like an aggregate (or totals) query, the domain functions build a resultset (that is, a set of records) and then apply a function to it. Unlike a query, however, a domain function can return ONLY one value.
Access has several built-in domain functions, the most common of which are: DCount(), DLookup(), DSum(), DAvg(), DMax(), DMin(), DFirst(), and DLast().
- DCount() returns the number of records of the resultset.
- DLookup() returns the value of a field in the resultset. If the resultset has multiple values, it returns the first one.
- DAvg() averages the values of the indicated field of the resultset.
- DMax() and DMin() find the highest and lowest values (respectively) of the resultset.
- DFirst() and DLast() finds the first and last values (respectively) of the resultset.
Note: At first glance, DFirst and DLast appear to be same as the DMax and DMin, but it they're really very different. DFirst returns the very first record in the recordset, which may not be the minimum value. Likewise, the last record in the recordset may not be the maximum. In general, I avoid DFirst and DLast as being less than useful.
One popular myth is that domain functions are slower than other methods. This is not true. In some cases, the domain functions can be as fast or faster than other methods. If performance is an issue, you should test both methods to and see which performs better.
Syntax
Domain functions have three arguments (the third is optional, however). The syntax is as follows:
DFunctionName("<Fieldname >", "<RecordSource>", "<Criteria Expression>")
- Fieldname refers to the field against which the function will be applied.
- RecordSource refers to a table or query from which the records will be pulled.
- Criteria Expression is basically an SQL Where clause without the WHERE keyword. (optional)
Each argument must be a string expression and must, therefore, be surrounded with quotes. This can be a problem when the Criteria Expression must also have quotes in it. I'll get to that a bit later.
Just like SQL Where clauses, some values must be delimited and others are not. For instance:
- Numeric values do not need delimiters (DLookup example below).
- Date values need the # delimiter around them (DMax example below).
- Strings need either the apostrophe (') or quote (") delimiters (DSum example below).
Examples of Simple Domain functions
- DCount("EmpID", "tblEmployee")Counts the number of records in the Employee table
- DLookup("SSN", "tblEmployee", "[EmpID] = 16")Returns the social security number of employee number 16.
- DMax("OrderDate", "tblOrders", "[OrderDate] < #1/1/2009#")Returns the latest order date from the Orders table which is before 1/1/2009
- DAvg("Cost", "tblProduct", "[Category] = 'printer'")
Returns the average cost of all printers from the Products table. - DSum("Cost", tblProduct", "[Category] = 'printer' AND [Manufacturer] = 'Epson'"or
DSum("Cost", tblProduct", "[Category] = ""printer"" AND [Manufacturer] = ""Epson"""
Returns the total cost of Epson printers from the Products table.
Variables in Criteria Expressions
So far, I've just used hard-coded values in the Criteria Expression. That's not the most useful application of domain functions. Domain functions become most useful when you use a variable for the value in the Criteria Expression.
For instance,
DSum("Price", "tblOrderDetails", "[OrderNum] = 1")
will return the total price for a particular order (1). (The value is not delimited with quotes in this case because order number is a numeric field.) But if I put this expression in the control source of a textbox on a continuous form, it would always show the same value, regardless of the other values on the screen.

DSum("Price", "tblOrderDetails", "[OrderNum] = " & Me.txtOrderID)

Criteria expressions in domain functions are confusing, so it might be useful to take a closer look at them, which I will do in my next post: Domain Functions Demystified: Criteria Expressions.
.
Thursday, December 2, 2010
Should I use the Compact On Close feature of Access?
I generally try to dissuade people from using the Compacting on Close feature of Microsoft Access, especially in a multi-user environment. Why?
Well, there are a variety of problems.
First of all, if your database bloats so quickly that it needs to be compacted every time it closes, then you have a design issue that should be addressed. See my blog post: How can I How Can I Compact my Access Database Less Often?
The two major causes of bloat are 1) importing data to a temporary table for processing and 2) creating temporary, intermediary tables with Make-table queries or other methods.
The data import problem can be addressed by linking a table or file for processing rather than importing it. If it can't be linked, it can be imported into a second, temporary database and then linked. This temporary database can be deleted later. I have a sample on my website called ImportToTempDatabase.mdb, which illustrates how to do this.
The problem of intermediate tables can also be solved by use of a temporary, local database which you create at startup and delete on database close. The solution is similar to the data import solution.
Secondly, compacting a database that doesn't need it will actually slow down the database some. Not a lot, perhaps, but some. Every database needs working space that Access has to create. If your database grows a lot on first opening. but then very little on subsequent uses, this isn't bloat. It's the normal working space that your database needs. Removing that working space every time you close the database requires Access to create it again the next time you use it.
Thirdly, it may be useless. A majority of Access databases are (or should be) in a Front-End/Back-End (FE/BE) configuration. This is often called a "split" database, where the tables reside in a separate database from the one which holds the queries, forms, reports, and code. Compacting on Close will only effect the database actually being used, which in most cases is going to be the FE. Unfortunately, it is the BE where the bloat actually occurs, so at best, compacting on close is useless, at worst, it's actively dangerous. Which leads me to the next point.
Fourth, and most importantly, there is a chance of database corruption any time you compact the database. Admittedly, with more reliable networking hardware and software, this chance is smaller than in years past, but it's still there. A small database on your local drive probably has little chance of corruption. However, even a single-user database if it's very large and on a network has a chance of some network glitch causing the whole compact/repair to fail. A failure during a compact means the database is toast. There is no recovery.
A large, multi-user database on a network has a much greater chance of failure.
So, I prefer to do a compact as a deliberate action rather than a hidden default. Often, when compacting a large database on the network, I will copy it to my local drive, compact it locally, then upload it back to the network. This gives me a backup in case anything goes wrong.
Also, if you compact the database programmatically (I have samples on my website: CompactDatabase.mdb and CompactBackEndDB.mdb), you have control to make a backup if you wish.
Friday, November 5, 2010
Office DEVCON in Australia
Today, I'm in Australia, speaking at the Office DEVCON 2010. I'm very excited to be asked to present here and it's a wonderful opportunity to see Australia.
My topic is: Data Warehouse in Access. Ridiculous? Not so!
The premise is that there is nothing inherent in the definition of a data warehouse that excludes the use of Access as an implementation platform. Certainly, Access has limitations of size and speed, and I'm not proposing its use as an Enterprise Data Warehouse. What I am proposing, however, is you can use the principles of data warehousing (dimensional model, calculated columns, etc) to make a super fast reporting database for your transactional system, especially with respect to aggregate data reporting.
There are two sessions. Part 1 discusses the structure of an Access data warehouse (or data mart if it makes you more comfortable). Part 2 discusses various methods of reporting from your warehouse/mart.
For those interested, the session PowerPoint presentations and accompaning articles can be downloaded here:
Datawarehouse_in_Access_Part_1.zip (3 MB)
Datawarehouse_in_Access_Part_2.zip (3.7 MB)
Office Automation Samples:
ExportToExcelCharts.mdb
AutomatingWordFromAccess.mdb
.
My topic is: Data Warehouse in Access. Ridiculous? Not so!
The premise is that there is nothing inherent in the definition of a data warehouse that excludes the use of Access as an implementation platform. Certainly, Access has limitations of size and speed, and I'm not proposing its use as an Enterprise Data Warehouse. What I am proposing, however, is you can use the principles of data warehousing (dimensional model, calculated columns, etc) to make a super fast reporting database for your transactional system, especially with respect to aggregate data reporting.
There are two sessions. Part 1 discusses the structure of an Access data warehouse (or data mart if it makes you more comfortable). Part 2 discusses various methods of reporting from your warehouse/mart.
For those interested, the session PowerPoint presentations and accompaning articles can be downloaded here:
Datawarehouse_in_Access_Part_1.zip (3 MB)
Datawarehouse_in_Access_Part_2.zip (3.7 MB)
Office Automation Samples:
ExportToExcelCharts.mdb
AutomatingWordFromAccess.mdb
.
Thursday, October 14, 2010
New Sample: Form_TreeView3TierCascaded
by A.D. Tejpal
This sample db demonstrates three tier cascaded treeview control for student tests and grades, with two way synchronization visa-vis associated subforms.
Treeview at left displays classes and students while the second treeview shows different levels of tests for various subjects - for the class in question.
Third treeview displays test results for current student, showing date of current test and marks obtained. Grades can be entered / edited conveniently just by clicking the pertinent check boxes.
For convenient viewing, as soon as a given class node caption is clicked or navigated to (say by Up / Down arrow keys), it expands, displaying all student nodes belonging to that class. Simultaneously, all other class nodes get collapsed.
For navigation as well as editing, the treeview and subform are mutually synchronized. Any action on treeview is reflected on corresponding record in the subform and vice versa.
You can find the sample here:
http://www.rogersaccesslibrary.com/forum/Form-treeview3tiercascaded_topic548.html
.
This sample db demonstrates three tier cascaded treeview control for student tests and grades, with two way synchronization visa-vis associated subforms.
Treeview at left displays classes and students while the second treeview shows different levels of tests for various subjects - for the class in question.
Third treeview displays test results for current student, showing date of current test and marks obtained. Grades can be entered / edited conveniently just by clicking the pertinent check boxes.
For convenient viewing, as soon as a given class node caption is clicked or navigated to (say by Up / Down arrow keys), it expands, displaying all student nodes belonging to that class. Simultaneously, all other class nodes get collapsed.
For navigation as well as editing, the treeview and subform are mutually synchronized. Any action on treeview is reflected on corresponding record in the subform and vice versa.
You can find the sample here:
http://www.rogersaccesslibrary.com/forum/Form-treeview3tiercascaded_topic548.html
.
Thursday, October 7, 2010
New Sample: Form_DsContSetDisplayPos
Form_DsContSetDisplayPos
by A. D. Tejpal
This sample db demonstrates positioning of selected block of rows in desired manner in the display window. Datasheet as well as continuous forms are covered, with the option to set start position of first row of selected block at top, middle or bottom of display screen.
You can find the sample here: http://www.rogersaccesslibrary.com/forum/Form-dscontsetdisplaypos_topic547.html
.
by A. D. Tejpal
This sample db demonstrates positioning of selected block of rows in desired manner in the display window. Datasheet as well as continuous forms are covered, with the option to set start position of first row of selected block at top, middle or bottom of display screen.
You can find the sample here: http://www.rogersaccesslibrary.com/forum/Form-dscontsetdisplaypos_topic547.html
.
Tuesday, October 5, 2010
Normalizing City, State, and Zip
Recently, I ran into a question on the internet about normalization that I thought would be good to repeat.
THE QUESTION:
I'm toying with the idea of starting a new project, so I'm in brainstorming mode for table design. I'll be recording customer information in this application. Typical stuff: First and Last Names, Company, Street, Apt, City State and Zip, Phone numbers(s) and extensions, E-mail.
How do you guys recommend setting up the tables for City State and Zip? I was thinking that I would have:
TBL_General_State
PKStateID
StateAbbr (Limited to 2 letters)
StateName
TBL_General_City
PKCityID
FKStateID (Lookup to TBL__State)
CityName
TBL_General_Zip
PKZipID
FKCityID (Lookup to TBL__City
ZipCode
My customer information then would record only the zip code (PKZipID). And I could then use queries for the state, city, and zip information for forms, reports, etc.
Or is this beyond overkill?
ANSWER:
By strict normalization theory, having City, State, and Zip in the same table violates the 3rd Normal Form because there are functional dependencies between those fields. However, functional dependencies are not all the same. There are strong dependencies and weak dependencies.
A strong dependency is one in which the value of a dependent field MUST be changed if another field is changed. For instance, suppose I have Quantity, Price, and ExtendedPrice, where ExtendedPrice is a calculation of the other two. If I change either Quantity or Price, the ExtendedPrice MUST be changed.
A weak dependency is one in which the value of a dependent field MAY be changed if another field is changed. City, State, and Zip are examples of weak dependencies. If I change a person's city, I may not have to change their state. They may have moved within the same state. Likewise, if I change the state, I may not have to change the city. There is, after all, a Grand Rapids, Michigan and Grand Rapids, Minnesota. The relationship between city and zip is even more complicated.
Now, it is possible to represent these fields in a fully normalized fashion, but I contend that it is more trouble for very little gain. There are two main reasons for normalizing data: minimize redundant data and maximize data integrity. Both of these can be achieved by using lookup tables for City and State without trying to represent the relationship between the two. A zip code could be mis-typed, of course, but it could also be mis-selected from a list, so to my mind there's no real reason to have a lookup table.
If you did normalize these fields, you could have a selection process that would present all possible combinations of values if you selected the City. For instance, if you had a combo box for City, you could have cascading combo boxes to select only the appropriate States and Zip codes. But it would be just as easy to mis-select the right value from this list as it would be to mis-select from independent lookup tables. And, of course, you'd have to create and maintain these relationships.
Therefore, normalizing City, State, and Zip adds a complication to your data model for very little gain, and in my opinion, is a good example of when to denormalize.
.
Tuesday, September 28, 2010
Help! My Database is Corrupted, and I Can't Repair!
As a follow up to my recent series on compacting databases, I thought I should say a word about the repairing part of Compact and Repair.
As a file-based database system, Access is more susceptible to corruption than a server-based database like SQL Server. However, Access databases are not quite as fragile as many believe. The most common causes are external to Access: PC hardware problems, network problems, users shutting down Access, or killing the Access process when it is accessing the disk. A few are internal: use of the Name Autocorrect feature, multiple users using the same file, or memo fields. These last do not cause corruption, but corruption is more likely when used.
In my experience, most of the time a corrupt database can be fixed by Compact and Repair. I personally have had only one database that was not. That one happened when I lost network connection while I was compacting the database.
But although it doesn't happen often, Access databases can be corrupted beyond repair, or at least beyond the ability of Compact and Repair to fix. In some cases, you've no alternative but to resort to your backup. (You DO back up your database regularly, don't you?) But there are things you can try before you have to resort to that.
The following links are some of the standard references for recovering a corrupt database.
Jerry Whittle's Fix Corrupt Access Database v4.5
Allen Browne's Corruption Tips
Tony Toew's Corrupt Microsoft Access MDBs FAQ
.
As a file-based database system, Access is more susceptible to corruption than a server-based database like SQL Server. However, Access databases are not quite as fragile as many believe. The most common causes are external to Access: PC hardware problems, network problems, users shutting down Access, or killing the Access process when it is accessing the disk. A few are internal: use of the Name Autocorrect feature, multiple users using the same file, or memo fields. These last do not cause corruption, but corruption is more likely when used.
In my experience, most of the time a corrupt database can be fixed by Compact and Repair. I personally have had only one database that was not. That one happened when I lost network connection while I was compacting the database.
But although it doesn't happen often, Access databases can be corrupted beyond repair, or at least beyond the ability of Compact and Repair to fix. In some cases, you've no alternative but to resort to your backup. (You DO back up your database regularly, don't you?) But there are things you can try before you have to resort to that.
The following links are some of the standard references for recovering a corrupt database.
Jerry Whittle's Fix Corrupt Access Database v4.5
Allen Browne's Corruption Tips
Tony Toew's Corrupt Microsoft Access MDBs FAQ
.
Monday, September 27, 2010
New Sample: Form_Resize
Form_Resize
by AD Tejpal
This sample db demonstrates resizing of access forms so as to suit current screen resolution. In addition, user has the option to carry out custom resizing - if desired.
Five styles of demo forms are included as follows:
(a) Simple controls - all free to float and resize.
(b) Simple controls - with certain controls having tag property settings for locking their position and / or size.
(c) Combo box and list box.
(d) Nested subforms - Continuous.
(e) Nested subforms - Datasheet.
(f) Tab control having (i) Nested subforms and (ii) Option group.
Tag property settings for steering the behavior of individual controls are as follows (more than one setting (separated by ;) can be included in the tag string):
(a) LockLeft: The control retains a fixed distance from left edge of the form.
(b) LockRight: The control retains a fixed distance from right edge of the form.
(c) LockTop: The control retains a fixed distance from top edge of the form.
(d) LockBottom: The control retains a fixed distance from bottom edge of the form.
(e) LockLeftRight: The control expands in such a manner that its left edge retains the original distance from left edge of the form, while its right edge retains the original distance from right edge of the form.
(f) LockTopBottom: The control expands in such a manner that its top edge retains the original distance from top edge of the form, while its bottom edge retains the original distance from bottom edge of the form.
(g) LockSize: The control retains its original size.
(h) LockWidth: The control retains its original width.
(i) LockHeight: The control retains its original height.
Demo forms have all been designed for a screen resolution of 800 x 600. On opening any of these forms, it resizes automatically to suit the screen resolution currently in force (if it happens to be different from the designed one).
You can find the sample here: Form_Resize
.
by AD Tejpal
This sample db demonstrates resizing of access forms so as to suit current screen resolution. In addition, user has the option to carry out custom resizing - if desired.
Five styles of demo forms are included as follows:
(a) Simple controls - all free to float and resize.
(b) Simple controls - with certain controls having tag property settings for locking their position and / or size.
(c) Combo box and list box.
(d) Nested subforms - Continuous.
(e) Nested subforms - Datasheet.
(f) Tab control having (i) Nested subforms and (ii) Option group.
Tag property settings for steering the behavior of individual controls are as follows (more than one setting (separated by ;) can be included in the tag string):
(a) LockLeft: The control retains a fixed distance from left edge of the form.
(b) LockRight: The control retains a fixed distance from right edge of the form.
(c) LockTop: The control retains a fixed distance from top edge of the form.
(d) LockBottom: The control retains a fixed distance from bottom edge of the form.
(e) LockLeftRight: The control expands in such a manner that its left edge retains the original distance from left edge of the form, while its right edge retains the original distance from right edge of the form.
(f) LockTopBottom: The control expands in such a manner that its top edge retains the original distance from top edge of the form, while its bottom edge retains the original distance from bottom edge of the form.
(g) LockSize: The control retains its original size.
(h) LockWidth: The control retains its original width.
(i) LockHeight: The control retains its original height.
Demo forms have all been designed for a screen resolution of 800 x 600. On opening any of these forms, it resizes automatically to suit the screen resolution currently in force (if it happens to be different from the designed one).
You can find the sample here: Form_Resize
.
Friday, September 24, 2010
How Can I Compact my Access Database Less Often?
So far in this series, I have talked about what compacting is, how it works, and several ways to compact, both through the Access Interface and in VBA code. However, one subject that's rarely discussed is how to reduce the need to compact the database in the first place. The number one reason for compacting is due to "database bloat", where records are added, deleted, and the space is not recovered until compacted. Reducing bloat will reduce the frequency of having to compact your database.
Here are some strategies:
Split the Database (FE/BE)
A split database is one in which the application (queries, forms, reports, macros, and code) are in a separate physical database file (known as the Front-End or FE) from the tables (which file is known as the Back-End or BE). Since bloating affects the tables most, having them in their own file means that only the BE needs to be compacted. As I showed last time, this can be initiated from the FE fairly easily.
There are other good reasons besides this to split your database, including improved multi-user access and less corruption. Splitting the database is such a good idea, in fact, that I recommend it for almost every application.
Importing Data
Just as bloat is the number one reason for compacting, importing data is the number one reason for bloat. A common scenario is importing at text file to a temporary table, massaging or formatting the data in some way, appending it to the permanent table, then deleting the temp table. As we've seen, while Access with grow the database dynamically, it will not automatically shrink it when the data is deleted. If you import a lot of data this way, you can find yourself needing to compact often. There are a couple of ways around this:
Linking Files
Instead of importing files to a temporary table, consider linking them. You can link many kinds of files including external Access tables, Excel files, text files, or other external sources. These linked tables do not contribute to bloat nearly as much as importing them, although as we'll see later, processing them may cause some database growth. Of course any time you add records to your database, the file size will grow. Nothing can be done about that. But minimizing the amount of temporary data you import to your database will keep growth within normal bounds.
Importing to temp database
If you must import data to a table for some reason, consider creating a temporary database to store the data and link those tables into your database. After you're done with the import process, the temporary database can be deleted. You an even create, populate, link, process, and delete temporary databases programmatically from your FE application. On my website is a small sample database called ImportToTempDatabase.mdb which illustrates how.
Don't obsess - some "bloat" is okay
Not all bloat is bad. Some of it is necessary. Aside from inserting and deleting records, databases can grow due to internal processing. When the database engine runs a query or a recordset based on a query, it has to process and store it somewhere, and that "somewhere" can cause your database to grow. This growth is not a cause for concern.
If you find that immediately after compacting your database grows dynamically at first, but then slows to minimal growth, that first, dramatic growth is just Access creating the working space it needs.
.
Here are some strategies:
Split the Database (FE/BE)
A split database is one in which the application (queries, forms, reports, macros, and code) are in a separate physical database file (known as the Front-End or FE) from the tables (which file is known as the Back-End or BE). Since bloating affects the tables most, having them in their own file means that only the BE needs to be compacted. As I showed last time, this can be initiated from the FE fairly easily.
There are other good reasons besides this to split your database, including improved multi-user access and less corruption. Splitting the database is such a good idea, in fact, that I recommend it for almost every application.
Importing Data
Just as bloat is the number one reason for compacting, importing data is the number one reason for bloat. A common scenario is importing at text file to a temporary table, massaging or formatting the data in some way, appending it to the permanent table, then deleting the temp table. As we've seen, while Access with grow the database dynamically, it will not automatically shrink it when the data is deleted. If you import a lot of data this way, you can find yourself needing to compact often. There are a couple of ways around this:
Linking Files
Instead of importing files to a temporary table, consider linking them. You can link many kinds of files including external Access tables, Excel files, text files, or other external sources. These linked tables do not contribute to bloat nearly as much as importing them, although as we'll see later, processing them may cause some database growth. Of course any time you add records to your database, the file size will grow. Nothing can be done about that. But minimizing the amount of temporary data you import to your database will keep growth within normal bounds.
Importing to temp database
If you must import data to a table for some reason, consider creating a temporary database to store the data and link those tables into your database. After you're done with the import process, the temporary database can be deleted. You an even create, populate, link, process, and delete temporary databases programmatically from your FE application. On my website is a small sample database called ImportToTempDatabase.mdb which illustrates how.
Don't obsess - some "bloat" is okay
Not all bloat is bad. Some of it is necessary. Aside from inserting and deleting records, databases can grow due to internal processing. When the database engine runs a query or a recordset based on a query, it has to process and store it somewhere, and that "somewhere" can cause your database to grow. This growth is not a cause for concern.
If you find that immediately after compacting your database grows dynamically at first, but then slows to minimal growth, that first, dramatic growth is just Access creating the working space it needs.
.
Wednesday, September 22, 2010
How Can I Compact the Current Access Database in Code?
In my previous two posts: (What Does It Mean to Compact My Access Database? and How Do I Compact an Access Database?), I discussed what compacting a database does and how to do it through the Access User Interface. But it is also possible to use VBA code to do it as well.
Why would you want to use code? Well, if you're making an application for others to use, you might want to give them a button to compact the database so they don't have to know the menu/ribbon selections. You may also want to control when or how the compacting is done.
accDoDefaultAction Method
In Access 2003, it was possible compact the current database with the following code:
You cannot compact the open database by running a macro or Visual Basic code.
Well, that's not exactly true.
Send Keys Method
The Send Keys method is a way of sending keystrokes in code to the Access Interface. Since the menu/ribbon is different depending on your context (and which version of Access you're using) the send keys argument can vary quite a bit.
First of all, you need to put the code in an Event Procedure behind a button on a form. This will give us the form menu/ribbon context.
Access 2003: Sendkeys "%(TDC)", False
Access 2007: Sendkeys "%(FMC)", False
Access 2010: Sendkeys "%(YC)", False
I'm not really partial to that solution, though, because, as I said, I don't like to rely on a specific key sequence that can vary from context to context and version to version.
DAO CompactDatabase Method
A better solution, I think, is to use the DAO CompactDatabase method. The downside is that you can't use that on the current database. The workaround for that is to:
The CompactDatabase method can also be used on an external database (in fact, it's easier to do so.) This is useful if you have split your database into a Front-End and a Back-End. You can use the CompactDatabase method directly from the Front-End against the Back-End. The BE, which stores the tables, is generally the one that needs compacting most. I've also got a sample called CompactBackEndDB.mdb which illustrates this.
The real usefulness of the DAO method is the safety and flexibility you have. Instead of deleting the old database, you can rename it (say, by adding a date to the file name) so that you keep a backup. In fact, the CompactDatabase method can also be used simply to create a backup of the database.
Compacting With ADO
For completeness, I should mention it's also possible to compact a database with ADO. However, since I have no direct experience with it (I prefer DAO), I'll just give a Microsoft knowledge base article on the subject: http://support.microsoft.com/kb/230501/en-us.
Compacting Less Often
No discussion of compacting would be complete without addressing methods to reduce the need to compact in the first place. I'll conclude this series next time with that.
.
Why would you want to use code? Well, if you're making an application for others to use, you might want to give them a button to compact the database so they don't have to know the menu/ribbon selections. You may also want to control when or how the compacting is done.
accDoDefaultAction Method
In Access 2003, it was possible compact the current database with the following code:
- CommandBars("Menu Bar"). _
Controls("Tools"). _
Controls("Database utilities"). _
Controls("Compact and repair database..."). _
accDoDefaultAction
- CommandBars("Menu Bar").Enabled = True
CommandBars("Menu Bar"). _
Controls("Tools"). _
Controls("Database utilities"). _
Controls("Compact and repair database"). _
accDoDefaultAction
You cannot compact the open database by running a macro or Visual Basic code.
Well, that's not exactly true.
Send Keys Method
The Send Keys method is a way of sending keystrokes in code to the Access Interface. Since the menu/ribbon is different depending on your context (and which version of Access you're using) the send keys argument can vary quite a bit.
First of all, you need to put the code in an Event Procedure behind a button on a form. This will give us the form menu/ribbon context.
Access 2003: Sendkeys "%(TDC)", False
Access 2007: Sendkeys "%(FMC)", False
Access 2010: Sendkeys "%(YC)", False
I'm not really partial to that solution, though, because, as I said, I don't like to rely on a specific key sequence that can vary from context to context and version to version.
DAO CompactDatabase Method
A better solution, I think, is to use the DAO CompactDatabase method. The downside is that you can't use that on the current database. The workaround for that is to:
- Programmatically create a new, temporary database
- Copy several pre-created forms, macros and modules to this temp database
- Close the main database and launch temporary database with the /x switch which initiates the compact process.
- After compacting is done, close temp database and relaunch main database
The CompactDatabase method can also be used on an external database (in fact, it's easier to do so.) This is useful if you have split your database into a Front-End and a Back-End. You can use the CompactDatabase method directly from the Front-End against the Back-End. The BE, which stores the tables, is generally the one that needs compacting most. I've also got a sample called CompactBackEndDB.mdb which illustrates this.
The real usefulness of the DAO method is the safety and flexibility you have. Instead of deleting the old database, you can rename it (say, by adding a date to the file name) so that you keep a backup. In fact, the CompactDatabase method can also be used simply to create a backup of the database.
Compacting With ADO
For completeness, I should mention it's also possible to compact a database with ADO. However, since I have no direct experience with it (I prefer DAO), I'll just give a Microsoft knowledge base article on the subject: http://support.microsoft.com/kb/230501/en-us.
Compacting Less Often
No discussion of compacting would be complete without addressing methods to reduce the need to compact in the first place. I'll conclude this series next time with that.
.
Wednesday, September 15, 2010
How Do I Compact an Access Database?
In my previous post (What Does It Mean to Compact My Access Database?) I talked about what compacting an Access database is. In this post, I'm going to discuss how to do it. As with most things in Access, there are a number of ways, and the specifics change from version to version.
Compact On Close
I'm starting with Compact On Close to get it out of the way. Few experienced Access developers recommend this option.
Steps by version:
Access 2003: Tools > Options > General > Compact On Close (checkbox)
Access 2007: Office Button > Access Options > Current Database > Compact On Close (checkbox)
Access 2010: File > Options > Current Database > Compact On Close (checkbox)
While regular compacting can be good for performance, it's rare that a database needs to be compacted *every* time it closes. If it does, there are steps you can take to reduce that necessity (I'll address that in a later post.) But the real problem with Compact on Close is the risk of database corruption. Anytime you compact your database, there is a small risk of corrupting it. When you do it every time you close the database, the changes increase simply due to its frequency. This is why most of us discourage the use of Compact On Close.
Compacting the Current Database in the UI
In Access, you can compact the current database from the Menu/Ribbon as long as you are the only one that has it open.
Steps by version:
Access 2003: Tools > Database Utilities > Compact and Repair Database...
Access 2007: Office Button> Manage > Compact and Repair Database
Access 2010: Database Tools tab > Compact and Repair Database
As I said in my last post, the compact process writes the records to a new database, deletes the old one, and renames the new one to the old name. This is where the risk of corruption comes into it. If something happens during the write process -- say, by a network interruption -- the new database can be corrupted and when the old one is deleted, you've lost your only good copy.
I have had this happen to me. A database that's corrupted during compacting is, in my experience, corrupted beyond repair. But I have to say that I believe later Access versions are better at ensuring corruption doesn't happen. Still, there's always a risk. That's why it's a good idea to make a copy of your database before compacting it.
Because network glitches can cause corruption, it is sometimes advisable (and faster) to copy a network database to a local drive, compact it, then copy it back up to the network. This has the added benefit of preserving a the original while you compact it.
Compact Another Database in the Access UI
You can also compact a database that is not open (that is, the current database) in Access. To do this, you must have Access open, but have no database open.
Steps by version:
*With No database open in Access*
Access 2003: Tools > Database Utilities > Compact and Repair Database...
Access 2007: Office Button> Manage > Compact and Repair Database
Access 2010: Database Tools tab > Compact and Repair Database
The steps are nearly the same as compacting the current database, but it will give you two dialog boxes, one (Database to Compact From) asking for the name of the file to be compacted, and a second (Compact Database Into) asking for the name you want to give to the new database. Using this method, you *cannot* give it the same name as the original, so it safeguards your original database. It also means, however, that you'll have to do the renaming manually.
Using Code
There are several ways to compact a database in code, both the current database and an external database. There's enough here to fill a post of its own, so that's will I'll address next in How Can I Compact my Access Database Less Often?
.
Compact On Close
I'm starting with Compact On Close to get it out of the way. Few experienced Access developers recommend this option.
Steps by version:
Access 2003: Tools > Options > General > Compact On Close (checkbox)
Access 2007: Office Button > Access Options > Current Database > Compact On Close (checkbox)
Access 2010: File > Options > Current Database > Compact On Close (checkbox)
While regular compacting can be good for performance, it's rare that a database needs to be compacted *every* time it closes. If it does, there are steps you can take to reduce that necessity (I'll address that in a later post.) But the real problem with Compact on Close is the risk of database corruption. Anytime you compact your database, there is a small risk of corrupting it. When you do it every time you close the database, the changes increase simply due to its frequency. This is why most of us discourage the use of Compact On Close.
Compacting the Current Database in the UI
In Access, you can compact the current database from the Menu/Ribbon as long as you are the only one that has it open.
Steps by version:
Access 2003: Tools > Database Utilities > Compact and Repair Database...
Access 2007: Office Button> Manage > Compact and Repair Database
Access 2010: Database Tools tab > Compact and Repair Database
As I said in my last post, the compact process writes the records to a new database, deletes the old one, and renames the new one to the old name. This is where the risk of corruption comes into it. If something happens during the write process -- say, by a network interruption -- the new database can be corrupted and when the old one is deleted, you've lost your only good copy.
I have had this happen to me. A database that's corrupted during compacting is, in my experience, corrupted beyond repair. But I have to say that I believe later Access versions are better at ensuring corruption doesn't happen. Still, there's always a risk. That's why it's a good idea to make a copy of your database before compacting it.
Because network glitches can cause corruption, it is sometimes advisable (and faster) to copy a network database to a local drive, compact it, then copy it back up to the network. This has the added benefit of preserving a the original while you compact it.
Compact Another Database in the Access UI
You can also compact a database that is not open (that is, the current database) in Access. To do this, you must have Access open, but have no database open.
Steps by version:
*With No database open in Access*
Access 2003: Tools > Database Utilities > Compact and Repair Database...
Access 2007: Office Button> Manage > Compact and Repair Database
Access 2010: Database Tools tab > Compact and Repair Database
The steps are nearly the same as compacting the current database, but it will give you two dialog boxes, one (Database to Compact From) asking for the name of the file to be compacted, and a second (Compact Database Into) asking for the name you want to give to the new database. Using this method, you *cannot* give it the same name as the original, so it safeguards your original database. It also means, however, that you'll have to do the renaming manually.
Using Code
There are several ways to compact a database in code, both the current database and an external database. There's enough here to fill a post of its own, so that's will I'll address next in How Can I Compact my Access Database Less Often?
.
Friday, September 10, 2010
What Does It Mean to Compact My Access Database?
Access databases are designed to grow dynamically as data is added. Access will also create working space to manipulate data. However, while it will grow dynamically, it does not shrink automatically when records are deleted or when it's data maniulation is done.
What's more, as data is added and deleted, the database can become fragmented (much like a hard disk is fragmented), and records can be stored out of primary key order. All of this can degrade the performance of your database, especially as it gets larger.
Compacting the database corrects these problems.
But before I get to that, it's important to understand exactly how compacting works because and existing file is not actually compacted. Here's what actually happens:
First of all, the database is "defragmented", that is, it rearranges how the file is stored on the disk. This is different than a disk defrag, but the effect is much the same: putting data into contiguous blocks. In this process, empty space is reclaimed, usually leaving the database file size smaller. This is the most common reason given for compacting, but perhaps not the most important.
Secondly, it rearranges the order of the records by writing them in primary key order. This is the equivalent of a Clustered Index in other database implementation and makes the read-ahead capabilities of the database engine more efficient.
Thirdly, it rebuilds the table statistics which are used by the query optimizer to optimize queries. It also forces a re-compile of your saved and embedded queries based on these new stastics.
Lastly, since technically it's called Compact and Repair, it will fix any page corruptions caused by hardware or network problems.
There are some limitations, however. Since Compacting writes the database to a new file, there must be enough hard drive space to hold both databases. You also can't compact a database is anyone else is in it. You must have exclusive access (although it doesn't have to opened in "exclusive" mode.) You can compact the current database (that is, the one you have open) through the Access User Interface, but not in code. (I'll discuss that in a later post.)
So, how exactly do you compact a database? There are several ways, both manual and programmatic, and I'll discuss that in my next post: How Do I Compact an Access Database?.
.
What's more, as data is added and deleted, the database can become fragmented (much like a hard disk is fragmented), and records can be stored out of primary key order. All of this can degrade the performance of your database, especially as it gets larger.
Compacting the database corrects these problems.
But before I get to that, it's important to understand exactly how compacting works because and existing file is not actually compacted. Here's what actually happens:
- Access creates a new, blank database called db1.mdb (Access 2003-) or database1.accdb (Access 2007+).
- It writes the data in the original database to the new database, doing several things in the process:
- When the process completes successfully, it deletes the original database.
- Lastly, it renames the new database to the original database name.
First of all, the database is "defragmented", that is, it rearranges how the file is stored on the disk. This is different than a disk defrag, but the effect is much the same: putting data into contiguous blocks. In this process, empty space is reclaimed, usually leaving the database file size smaller. This is the most common reason given for compacting, but perhaps not the most important.
Secondly, it rearranges the order of the records by writing them in primary key order. This is the equivalent of a Clustered Index in other database implementation and makes the read-ahead capabilities of the database engine more efficient.
Thirdly, it rebuilds the table statistics which are used by the query optimizer to optimize queries. It also forces a re-compile of your saved and embedded queries based on these new stastics.
Lastly, since technically it's called Compact and Repair, it will fix any page corruptions caused by hardware or network problems.
There are some limitations, however. Since Compacting writes the database to a new file, there must be enough hard drive space to hold both databases. You also can't compact a database is anyone else is in it. You must have exclusive access (although it doesn't have to opened in "exclusive" mode.) You can compact the current database (that is, the one you have open) through the Access User Interface, but not in code. (I'll discuss that in a later post.)
So, how exactly do you compact a database? There are several ways, both manual and programmatic, and I'll discuss that in my next post: How Do I Compact an Access Database?.
.
Monday, August 2, 2010
Access 2010: Detect and Repair
Starting with Office XP, Microsoft introduced the Detect and Repair feature for all Office applications. This is different than the Access Compact and Repair in that it detected and repaired problems with the Office application itself (Word, Excel, Access, etc.) rather than a particular file.
In a way, it was like launching the Office Repair from Control Panel > Add/Remove Programs, except it targeted just the application you launched it from. If launched from Word, it would repair only Word. If launched from Excel, it would detect and repair problems in Excel only. If...well you get the idea.
Once launched, it brings up the Detect and Repair Wizard, which looks something like this:

In Access XP and Access 2003, Detect and Repair was launched from the Help Menu.

In Access 2007, they changed it to a more comprehensive utility called Microsoft Office Diagnostics, which is launched from Office Button > Access Options > Resources Tab > Diagnose.
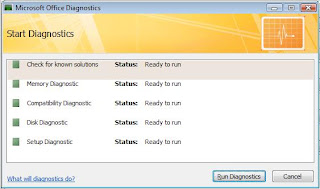
As far as I know, however, the option is not available in Access 2010, either from the menu system or the Ribbon. You can, however launch it in code:
Application.CommandBars.FindControl(ID:=3774).Execute

End Function
Create a macro that runs the function:

And lastly, add the macro to a custom group on the Ribbon.
.
In a way, it was like launching the Office Repair from Control Panel > Add/Remove Programs, except it targeted just the application you launched it from. If launched from Word, it would repair only Word. If launched from Excel, it would detect and repair problems in Excel only. If...well you get the idea.
Once launched, it brings up the Detect and Repair Wizard, which looks something like this:

In Access XP and Access 2003, Detect and Repair was launched from the Help Menu.

In Access 2007, they changed it to a more comprehensive utility called Microsoft Office Diagnostics, which is launched from Office Button > Access Options > Resources Tab > Diagnose.

Application.CommandBars.FindControl(ID:=3774).Execute
This will launch the original Detect and Repair.

If you want to add it to the Ribbon, you'd have to put the code in a function in a general module:
Function Detect_Repair()
Application.CommandBars.FindControl(ID:=3774).ExecuteEnd Function
Create a macro that runs the function:

.
Wednesday, July 28, 2010
How do I add a value to a combo box with Not In List?
The combo box control has a nifty event called NotInList. If the LimitToList property of my combo box is set to Yes, and I type a value that is not in the drop-down list, the NotInList event will fire. This will allow me to capture this event and add some programming to it.
Before I go further, I should explain that a combo box can have its drop-down list (the RowSource property) filled by a query, a field list or a value list. The scenario I'm addressing here is a the row source filled by a query from a separate look-up table.
So suppose I have a form where I want to fill in Employee information including what Training they've had. There's a combo box on the form called cboTraining that is filled from a table called tbxTraining that lists the available training opportunities (Word, Excel, etc.). Now suppose further that an employee takes a new type of training that is not already in the training table, say Access. Since I have LimitToList set to Yes, I can't just type "Access" into the training field. I have to select an item in the list. But I also don't want my data entry person to have to stop what they're doing, open the tbxTraining table, add the value, then go back to entering data.
This is where the NotInList event comes in. I can programmatically add the value to my tbxTraining table, refresh the combo box, and the data entry person can just continue on.
To add code to the combo's NotInList event, I open the form in design view and open the the property sheet of the combo box. In the NotInList event, choose [Event Procedure] in the drop-down list. The VBA editor will open with the first and last line of the subroutine already created. Something like this:
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
End Sub
What I'm going to discuss now is the code that goes between those two lines.
There are a number of different ways to implement adding a value to the drop-down list. Some are easier but dangerous. Others are harder to implement, but safer.
The easiest thing for me to do is to just automatically add a new value to my lookup table when a new type of training is added to the transaction table. To do this, I would add something like the following to my NotInList event of my combo box:
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
Dim strsql As String
MsgBox "Training type does not exist. Creating new Record in Training table."
strsql = "Insert Into [tbxTraining] ([Training]) values ('" & NewData & "')"
CurrentDb.Execute strsql, dbFailOnError
Response = acDataErrAdded
End Sub
You do want to be a little careful about allowing this depending on the data entry people. It's possible to get multiples of training with slight variations. For instance, a data entry person could add "Access" or "Access Database" to the training table, both of which would refer to the same type of training. I'm not saying this shouldn't be implemented, but you do need to be careful how you do it.
A little safer is to ask the user if they want to add it. That requires only a slight variation:
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
Dim strsql As String, x As Integer
x = MsgBox("Do you want to add this value to the list?", vbYesNo)
If x = vbYes Then
strsql = "Insert Into [tbxTraining] ([Training]) values ('" & NewData & "')"
CurrentDb.Execute strsql, dbFailOnError
Response = acDataErrAdded
Else
Response = acDataErrContinue
End If
End Sub
This can still give me logical duplicates if my user isn't careful. (Sometimes they'll just say "yes" without ever thinking about it, which is just as bad as the first option).
Another way that is even safer is to programmatically open the maintenance form (say, frmTraining) when the user types a value that isn't in the list, allow them to add the record manually, then save and return to the record in the transaction form.
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
Dim strsql As String, x As Integer
x = MsgBox("Do you want to add this value to the list?", vbYesNo)
If x = vbYes Then
DoCmd.OpenForm "frmTraining"
Response = acDataErrAdded
Else
Response = acDataErrContinue
End If
End Sub
There are other variations on this theme. On my website, I have a small sample database called NotInList.mdb which illustrates these and other options.
.
Before I go further, I should explain that a combo box can have its drop-down list (the RowSource property) filled by a query, a field list or a value list. The scenario I'm addressing here is a the row source filled by a query from a separate look-up table.
So suppose I have a form where I want to fill in Employee information including what Training they've had. There's a combo box on the form called cboTraining that is filled from a table called tbxTraining that lists the available training opportunities (Word, Excel, etc.). Now suppose further that an employee takes a new type of training that is not already in the training table, say Access. Since I have LimitToList set to Yes, I can't just type "Access" into the training field. I have to select an item in the list. But I also don't want my data entry person to have to stop what they're doing, open the tbxTraining table, add the value, then go back to entering data.
This is where the NotInList event comes in. I can programmatically add the value to my tbxTraining table, refresh the combo box, and the data entry person can just continue on.
To add code to the combo's NotInList event, I open the form in design view and open the the property sheet of the combo box. In the NotInList event, choose [Event Procedure] in the drop-down list. The VBA editor will open with the first and last line of the subroutine already created. Something like this:
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
End Sub
What I'm going to discuss now is the code that goes between those two lines.
There are a number of different ways to implement adding a value to the drop-down list. Some are easier but dangerous. Others are harder to implement, but safer.
The easiest thing for me to do is to just automatically add a new value to my lookup table when a new type of training is added to the transaction table. To do this, I would add something like the following to my NotInList event of my combo box:
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
Dim strsql As String
MsgBox "Training type does not exist. Creating new Record in Training table."
strsql = "Insert Into [tbxTraining] ([Training]) values ('" & NewData & "')"
CurrentDb.Execute strsql, dbFailOnError
Response = acDataErrAdded
End Sub
You do want to be a little careful about allowing this depending on the data entry people. It's possible to get multiples of training with slight variations. For instance, a data entry person could add "Access" or "Access Database" to the training table, both of which would refer to the same type of training. I'm not saying this shouldn't be implemented, but you do need to be careful how you do it.
A little safer is to ask the user if they want to add it. That requires only a slight variation:
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
Dim strsql As String, x As Integer
x = MsgBox("Do you want to add this value to the list?", vbYesNo)
If x = vbYes Then
strsql = "Insert Into [tbxTraining] ([Training]) values ('" & NewData & "')"
CurrentDb.Execute strsql, dbFailOnError
Response = acDataErrAdded
Else
Response = acDataErrContinue
End If
End Sub
This can still give me logical duplicates if my user isn't careful. (Sometimes they'll just say "yes" without ever thinking about it, which is just as bad as the first option).
Another way that is even safer is to programmatically open the maintenance form (say, frmTraining) when the user types a value that isn't in the list, allow them to add the record manually, then save and return to the record in the transaction form.
Private Sub cboTraining_NotInList(NewData As String, Response As Integer)
Dim strsql As String, x As Integer
x = MsgBox("Do you want to add this value to the list?", vbYesNo)
If x = vbYes Then
DoCmd.OpenForm "frmTraining"
Response = acDataErrAdded
Else
Response = acDataErrContinue
End If
End Sub
There are other variations on this theme. On my website, I have a small sample database called NotInList.mdb which illustrates these and other options.
.
Tuesday, July 20, 2010
Access 2010: Unrecognized Database Format
I've been seeing more and more people having problems with the Unrecognized Database Format when creating or modifying an Access 2007 (accdb) format database in Access 2010 and then trying to open it again in Access 2007.
The issue appears to be that Access 2010 does not have its own file format. When you add a feature that is specific to A2010 (like the navigation control, data macro, or calculated column), that file becomes forever unreadable to A2007, even if the new feature(s) are removed. The solution appears to be:
I'm told that it is also possible to make the original file A2007 readable by removing the A2010 features and then making a minor edit to the file in a Hex editor. But I'd be wary of that approach. Importing the objects to a new database is safer, more reliable, and frankly simpler.
The issue appears to be that Access 2010 does not have its own file format. When you add a feature that is specific to A2010 (like the navigation control, data macro, or calculated column), that file becomes forever unreadable to A2007, even if the new feature(s) are removed. The solution appears to be:
- Remove all the new features from the file in A2010
- Create a new, blank accdb format database in A2010
- Import all the objects from the old database to the new.
I'm told that it is also possible to make the original file A2007 readable by removing the A2010 features and then making a minor edit to the file in a Hex editor. But I'd be wary of that approach. Importing the objects to a new database is safer, more reliable, and frankly simpler.
Monday, July 19, 2010
New Sample: Form_TreeView_BOM
Form_TreeView_BOM
by A.D. Tejpal
This sample db demonstrates extraction of complete hierarchical chain of sub-assemblies and components for the selected item. The user can select the desired item either by selection via combo box or by using the navigation buttons on the master subform at top left, bound to the master table T_PartMaster. Fields PartName and UnitPrice are available for user interaction (i.e. editing or new entry). UnitPrice is to be entered only for base parts (items which are not meant to have any child assemblies or components)
For the selected item, complete hierarchical chain of sub-assemblies and components gets displayed in the lower subform at right. For base parts, total quantity as well as total price are also shown in respective columns. Summary information (like maximum nesting levels, number of distinct assemblies and base parts as well as total cost of base parts needed for the selected item) gets depicted in label caption at top of this subform. For convenient analysis, the user can select any of the following styles of display, via option group below this subform:
(a) All parts (Complete hierarchical chain).
(b) Assemblies only - arranged as per relevant nesting level.
(c) Assemblies only - Straight.
(d) Base parts only - arranged as per relevant nesting level.
(e) Base parts only - Straight.
Simultaneously, the hierarchical chain of sub-assemblies and components gets depicted as tree view. Total cost of base parts (i.e. items which have no child assemblies or components) also gets depicted at bottom of tree view. Contents of tree view remain in step with the latest selection (out of five listed above) in option group.
Also, there is two way synchronization between tree view and the lower subform at right. If the user selects any node in tree view, corresponding record in subform becomes the current record. Conversely, if the user navigates to any record in the subform, corresponding node in tree view assumes selected state. PartID of matching record in the subform gets highlighted in a manner similar to the shade signifying selected node in treeview.
As the user navigates through master subform at top left, the contents of tree view as well as the two subforms at right keep getting updated as per current selection (treating current PartID on master subform as the top item for which hierarchical chain is to be extracted).
You can find the sample here: http://www.rogersaccesslibrary.com/forum/topic545_post557.html#557
.
by A.D. Tejpal
This sample db demonstrates extraction of complete hierarchical chain of sub-assemblies and components for the selected item. The user can select the desired item either by selection via combo box or by using the navigation buttons on the master subform at top left, bound to the master table T_PartMaster. Fields PartName and UnitPrice are available for user interaction (i.e. editing or new entry). UnitPrice is to be entered only for base parts (items which are not meant to have any child assemblies or components)
For the selected item, complete hierarchical chain of sub-assemblies and components gets displayed in the lower subform at right. For base parts, total quantity as well as total price are also shown in respective columns. Summary information (like maximum nesting levels, number of distinct assemblies and base parts as well as total cost of base parts needed for the selected item) gets depicted in label caption at top of this subform. For convenient analysis, the user can select any of the following styles of display, via option group below this subform:
(a) All parts (Complete hierarchical chain).
(b) Assemblies only - arranged as per relevant nesting level.
(c) Assemblies only - Straight.
(d) Base parts only - arranged as per relevant nesting level.
(e) Base parts only - Straight.
Simultaneously, the hierarchical chain of sub-assemblies and components gets depicted as tree view. Total cost of base parts (i.e. items which have no child assemblies or components) also gets depicted at bottom of tree view. Contents of tree view remain in step with the latest selection (out of five listed above) in option group.
Also, there is two way synchronization between tree view and the lower subform at right. If the user selects any node in tree view, corresponding record in subform becomes the current record. Conversely, if the user navigates to any record in the subform, corresponding node in tree view assumes selected state. PartID of matching record in the subform gets highlighted in a manner similar to the shade signifying selected node in treeview.
As the user navigates through master subform at top left, the contents of tree view as well as the two subforms at right keep getting updated as per current selection (treating current PartID on master subform as the top item for which hierarchical chain is to be extracted).
You can find the sample here: http://www.rogersaccesslibrary.com/forum/topic545_post557.html#557
.
Monday, June 28, 2010
New Sample: RollingAverages.MDB
RollingAverages.MDB
by Roger Carlson
This sample illustrates two different ways to create a "Rolling Average" query. It averages the latest 13 months in the sequence.
| Sequence | tWeek | tValue | RollingAverage |
| 20 | Week 26 | 10 | 39.8461538461538 |
| 19 | Week 25 | 11 | 43.8461538461538 |
| 18 | Week 24 | 22 | 48.4615384615385 |
| 17 | Week 23 | 44 | 47.6923076923077 |
| 16 | Week 22 | 55 | 45.4615384615385 |
| 15 | Week 21 | 44 | 46.1538461538462 |
| 14 | Week 20 | 22 | 45.4615384615385 |
| 13 | Week 19 | 77 | 48.5384615384615 |
| 12 | Week 18 | 88 | 46.1666666666667 |
| 11 | Week 17 | 11 | 42.3636363636364 |
| 10 | Week 16 | 74 | 45.5 |
| 9 | Week 15 | 35 | 42.3333333333333 |
| 8 | Week 14 | 25 | 43.25 |
| 7 | Week 13 | 62 | 45.8571428571429 |
| 6 | Week 12 | 71 | 43.1666666666667 |
| 5 | Week 11 | 12 | 37.6 |
| 4 | Week 10 | 15 | 44 |
| 3 | Week 9 | 64 | 53.6666666666667 |
| 2 | Week 8 | 35 | 48.5 |
| 1 | Week 7 | 62 | 62 |
The first two use DCount and the second two use a Sub Query. You must identify a unique column in the query to create the sequence on. I used an autonumber ID field, which while in order, has gaps in it.
The DCount method creates an updateable recordset. The SubQuery method produced non-updateable recordsets.
You can find the sample here: RollingAverages.mdb.
.
Subscribe to:
Posts (Atom)